Web Scraping com Selenium e Python | Resolvendo Captcha ao fazer Web Scraping
Web Scraping com Selenium e Python | Resolvendo Captcha ao fazer Web Scraping
Adélia Cruz
Neural Network Developer
24-Jun-2024
Imagine que você pode obter facilmente todos os dados de que precisa na Internet sem ter que navegar manualmente na web ou copiar e colar. Essa é a beleza da raspagem web (web scraping). Quer você seja um analista de dados, pesquisador de mercado ou desenvolvedor, a raspagem web abre um mundo totalmente novo de coleta automatizada de dados.
Nesta era orientada por dados, a informa??o é poder. No entanto, extrair manualmente informa??es de centenas ou até milhares de páginas da web n?o é apenas demorado, mas também propenso a erros. Felizmente, a raspagem web fornece uma solu??o eficiente e precisa que permite automatizar o processo de extra??o dos dados necessários da Internet, melhorando muito a eficiência e a qualidade dos dados.
A raspagem web é uma técnica para extrair automaticamente informa??es de páginas da web escrevendo programas. Esta tecnologia tem uma ampla gama de aplica??es em muitos campos, incluindo análise de dados, pesquisa de mercado, inteligência competitiva, agrega??o de conteúdo e muito mais. Com a raspagem web, você pode coletar e consolidar dados de um grande número de páginas da web em um curto período de tempo, em vez de depender de opera??es manuais.
O processo de raspagem web geralmente inclui as seguintes etapas:
Enviar solicita??o HTTP: Enviar programaticamente uma solicita??o ao site alvo para obter o código-fonte HTML da página web. Ferramentas comumente usadas, como a biblioteca requests do Python, podem fazer isso facilmente.
Analisar o conteúdo HTML: Após obter o código-fonte HTML, é necessário analisá-lo para extrair os dados necessários. Bibliotecas de análise HTML, como BeautifulSoup ou lxml, podem ser usadas para processar a estrutura HTML.
Extrair dados: Com base na estrutura HTML analisada, localizar e extrair conteúdos específicos, como título do artigo, informa??es de pre?o, links de imagens, etc. Métodos comuns incluem o uso de XPath ou seletores CSS.
Armazenar dados: Salvar os dados extraídos em um meio de armazenamento adequado, como um banco de dados, arquivo CSV ou arquivo JSON, para posterior análise e processamento.
Além disso, ao usar ferramentas como o Selenium, é possível simular a opera??o do navegador do usuário, contornando alguns dos mecanismos anti-crawler, para assim completar a tarefa de raspagem web de forma mais eficiente.
Lutando com a falha repetida de resolver completamente o irritante captcha?
Descubra a resolu??o automática de captcha com a tecnologia de desbloqueio web automatizado com AI do Capsolver!
Reivindique seu Código de B?nus para as melhores solu??es de captcha; CapSolver: WEBS. Após resgatar, você receberá um b?nus extra de 5% após cada recarga, Ilimitado.
Introdu??o ao Selenium
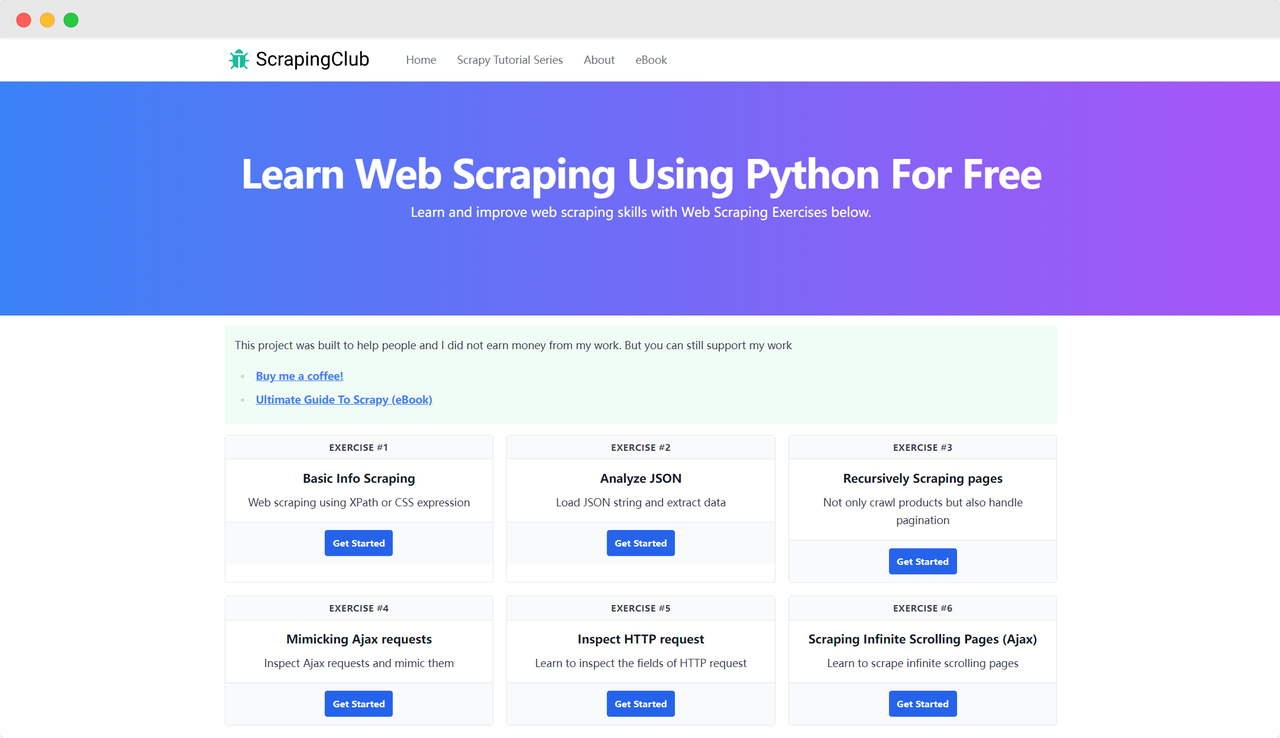
Vamos usar o ScrapingClub como exemplo e usar o Selenium para completar o primeiro exercício.
Prepara??o
Primeiro, você precisa garantir que o Python esteja instalado em sua máquina local. Você pode verificar a vers?o do Python digitando o seguinte comando em seu terminal:
bashCopy
python --version
Certifique-se de que a vers?o do Python seja maior que 3. Se n?o estiver instalado ou a vers?o for muito baixa, fa?a o download da vers?o mais recente no site oficial do Python. Em seguida, você precisa instalar a biblioteca selenium usando o seguinte comando:
bashCopy
pip install selenium
Importar bibliotecas
pythonCopy
from selenium import webdriver
Acessando uma página
Usar o Selenium para dirigir o Google Chrome para acessar uma página n?o é complicado. Após inicializar o objeto Chrome Options, você pode usar o método get() para acessar a página alvo:
pythonCopy
import time
from selenium import webdriver
chrome_options = webdriver.ChromeOptions()
driver = webdriver.Chrome(options=chrome_options)
driver.get('https://scrapingclub.com/')
time.sleep(5)
driver.quit()
Par?metros de inicializa??o
O Chrome Options pode adicionar muitos par?metros de inicializa??o que ajudam a melhorar a eficiência da recupera??o de dados. Você pode ver a lista completa de par?metros no site oficial: Lista de Switches de Linha de Comando do Chromium. Alguns par?metros comumente usados est?o listados na tabela abaixo:
Par?metro
Finalidade
--user-agent=""
Definir o User-Agent no cabe?alho da solicita??o
--window-size=xxx,xxx
Definir a resolu??o do navegador
--start-maximized
Executar com resolu??o maximizada
--headless
Executar no modo headless
--incognito
Executar no modo incógnito
--disable-gpu
Desativar acelera??o de hardware GPU
Exemplo: executando no modo headless
pythonCopy
import time
from selenium import webdriver
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--headless')
driver = webdriver.Chrome(options=chrome_options)
driver.get('https://scrapingclub.com/')
time.sleep(5)
driver.quit()
Localizando elementos da página
Um passo necessário na raspagem de dados é encontrar os elementos HTML correspondentes no DOM. O Selenium fornece dois métodos principais para localizar elementos na página:
find_element: Encontra um único elemento que atenda aos critérios.
find_elements: Encontra todos os elementos que atendam aos critérios.
Ambos os métodos suportam oito maneiras diferentes de localizar elementos HTML:
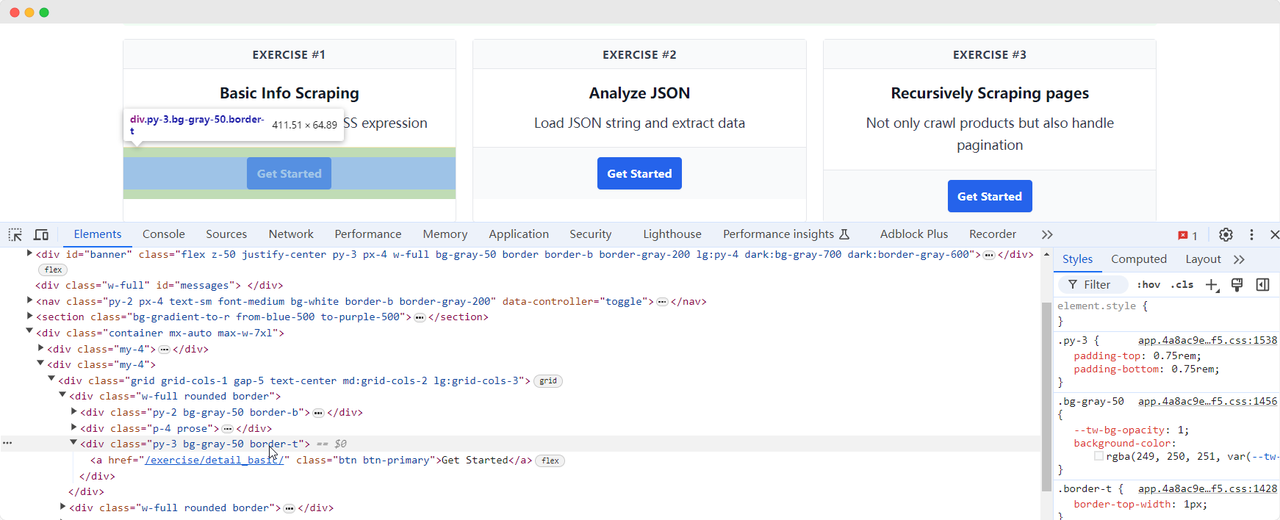
Vamos voltar à página do ScrapingClub e escrever o seguinte código para encontrar o elemento do bot?o "Get Started" para o primeiro exercício:
pythonCopy
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
chrome_options = webdriver.ChromeOptions()
driver = webdriver.Chrome(options=chrome_options)
driver.get('https://scrapingclub.com/')
get_started_button = driver.find_element(By.XPATH, "//div[@class='w-full rounded border
'][1]/div[3]")
time.sleep(5)
driver.quit()
Intera??o com elementos
Uma vez que encontramos o elemento do bot?o "Get Started", precisamos clicar no bot?o para entrar na próxima página. Isso envolve a intera??o com o elemento. O Selenium fornece vários métodos para simular a??es:
click(): Clicar no elemento;
clear(): Limpar o conteúdo do elemento;
send_keys(*value: str): Simular a entrada do teclado;
submit(): Enviar um formulário;
screenshot(filename): Salvar uma captura de tela da página.
Para mais intera??es, consulte a documenta??o oficial: WebDriver API. Vamos continuar a melhorar o código do exercício do ScrapingClub adicionando a intera??o de clique:
pythonCopy
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
chrome_options = webdriver.ChromeOptions()
driver = webdriver.Chrome(options=chrome_options)
driver.get('https://scrapingclub.com/')
get_started_button = driver.find_element(By.XPATH, "//div[@class='w-full rounded border'][1]/div[3]")
get_started_button.click()
time.sleep(5)
driver.quit()
Extra??o de dados
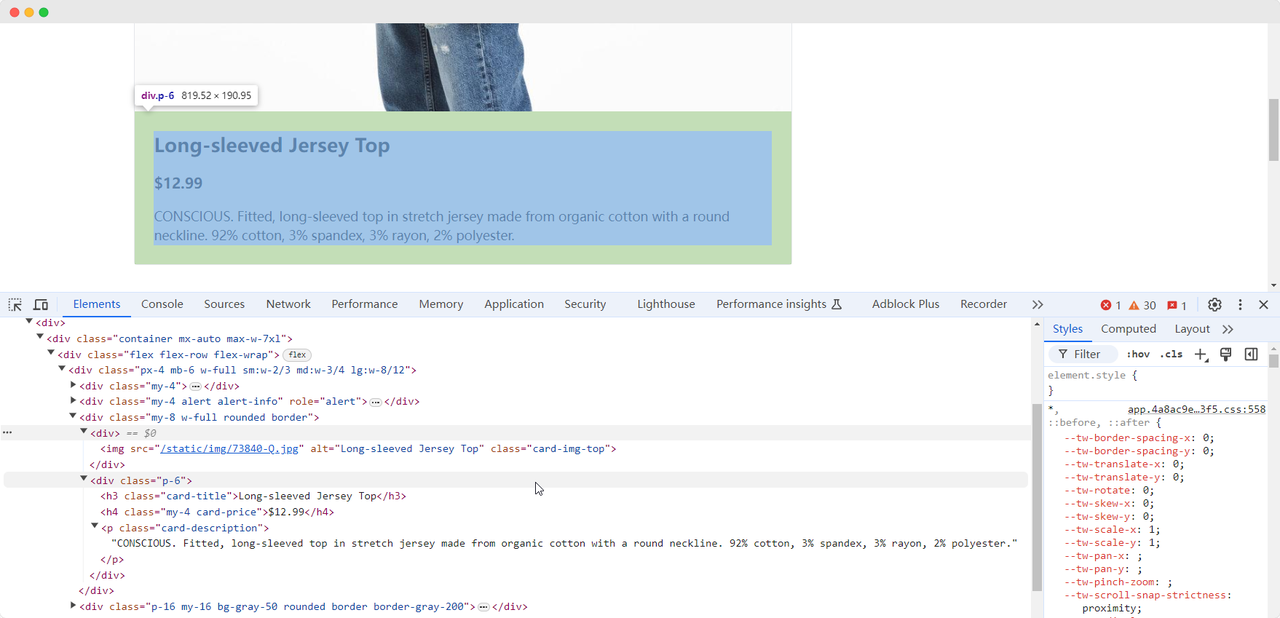
Quando chegamos à primeira página do exercício, precisamos coletar a imagem do produto, nome, pre?o e informa??es de descri??o. Podemos usar diferentes métodos para encontrar esses elementos e extraí-los:
Product name: Long-sleeved Jersey Top
Product image: https://scrapingclub.com/static/img/73840-Q.jpg
Product price: $12.99
Product description: CONSCIOUS. Fitted, long-sleeved top in stretch jersey made from organic cotton with a round neckline. 92% cotton, 3% spandex, 3% rayon, 2% polyester.
Esperando elementos carregarem
?s vezes, devido a problemas de rede ou outras raz?es, os elementos podem n?o ter carregado quando o Selenium terminar de executar, o que pode causar falha na coleta de alguns dados. Para resolver esse problema, podemos definir uma espera até que um determinado elemento esteja completamente carregado antes de prosseguir com a extra??o de dados. Aqui está um exemplo de código:
pythonCopy
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
chrome_options = webdriver.ChromeOptions()
driver = webdriver.Chrome(options=chrome_options)
driver.get('https://scrapingclub.com/')
get_started_button = driver.find_element(By.XPATH, "//div[@class='w-full rounded border'][1]/div[3]")
get_started_button.click()
# aguardando até que os elementos da imagem do produto estejam completamente carregados
wait = WebDriverWait(driver, 10)
wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, '.card-img-top')))
product_name = driver.find_element(By.CLASS_NAME, 'card-title').text
product_image = driver.find_element(By.CSS_SELECTOR, '.card-img-top').get_attribute('src')
product_price = driver.find_element(By.XPATH, '//h4').text
product_description = driver.find_element(By.CSS_SELECTOR, '.card-description').text
print(f'Product name: {product_name}')
print(f'Product image: {product_image}')
print(f'Product price: {product_price}')
print(f'Product description: {product_description}')
driver.quit()
Contornando Prote??es Anti-Raspagem
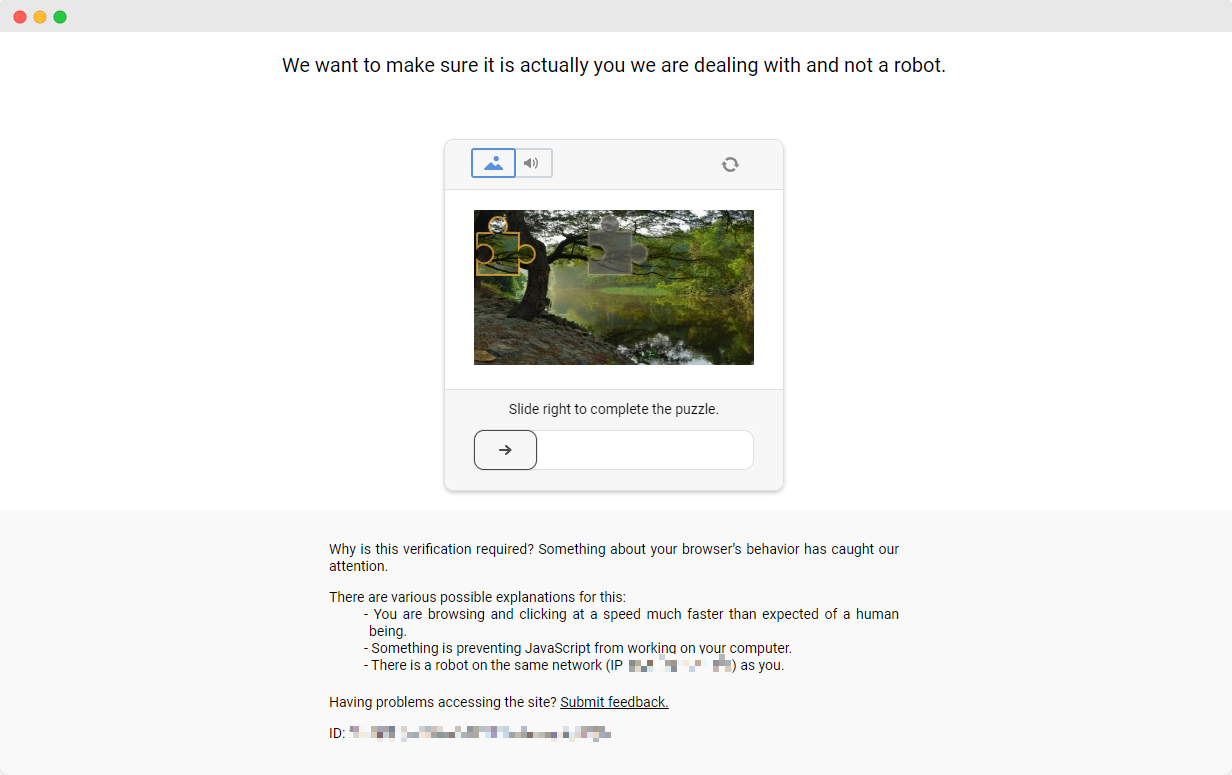
O exercício do ScrapingClub é fácil de completar. No entanto, em cenários reais de coleta de dados, obter dados n?o é t?o fácil porque alguns sites empregam técnicas anti-raspagem que podem detectar seu script como um bot e bloquear a coleta. A situa??o mais comum s?o os desafios de captcha.
Resolver esses desafios de captcha requer vasta experiência em aprendizado de máquina, engenharia reversa e contramedidas de impress?o digital do navegador, o que pode levar muito tempo. Felizmente, agora você n?o precisa fazer todo esse trabalho sozinho. CapSolver fornece uma solu??o completa para ajudá-lo a contornar todos os desafios facilmente. CapSolver oferece extens?es de navegador que podem resolver automaticamente os desafios de captcha enquanto usa o Selenium para coletar dados. Além disso, eles fornecem métodos de API para resolver captchas e obter tokens, tudo em apenas alguns segundos. Consulte a Documenta??o do CapSolver para mais informa??es.
Conclus?o
Desde a extra??o de detalhes do produto até a navega??o por medidas complexas de anti-raspagem, a raspagem web com Selenium abre portas para um vasto mundo de coleta automatizada de dados. ? medida que navegamos pelo cenário em constante evolu??o da web, ferramentas como o CapSolver pavimentam o caminho para uma extra??o de dados mais tranquila, tornando desafios outrora formidáveis uma coisa do passado. Portanto, quer você seja um entusiasta de dados ou um desenvolvedor experiente, aproveitar essas tecnologias n?o só melhora a eficiência, mas também desbloqueia um mundo onde insights orientados por dados est?o a apenas uma raspagem de dist?ncia.
Declara??o de Conformidade: As informa??es fornecidas neste blog s?o apenas para fins informativos. A CapSolver está comprometida em cumprir todas as leis e regulamentos aplicáveis. O uso da rede CapSolver para atividades ilegais, fraudulentas ou abusivas é estritamente proibido e será investigado. Nossas solu??es de resolu??o de captcha melhoram a experiência do usuário enquanto garantem 100% de conformidade ao ajudar a resolver dificuldades de captcha durante a coleta de dados públicos. Incentivamos o uso responsável de nossos servi?os. Para mais informa??es, visite nossos Termos de Servi?o e Política de Privacidade.