# O que é Web Scraping | Casos de Uso Comuns e Problemas
O que é Web Scraping | Casos de Uso Comuns e Problemas
Adélia Cruz
Neural Network Developer
05-Jul-2024
Talvez você tenha ouvido um ditado sobre dados sendo chamados de novo petróleo na sociedade da informa??o atual. Devido ao grande volume de informa??es disponíveis online, a capacidade de coletar e analisar dados da web de maneira eficaz tornou-se uma habilidade essencial para empresas, pesquisadores e desenvolvedores. ? aqui que o web scraping entra em cena. O web scraping, também conhecido como extra??o de dados da web, é uma tecnologia poderosa usada para coletar automaticamente informa??es de sites. Imagine poder obter uma grande quantidade de informa??es-chave de um site sem ter que copiar e colar manualmente os dados, mas o web scraping deve ser usado com cuidado e conformidade. Este blog apresentará brevemente o web scraping e abordará alguns dos problemas que você pode encontrar. Também discutirá alguns casos comuns de uso.
Entendendo o Web Scraping
O web scraping envolve o uso de ferramentas de software automatizadas, conhecidas como scrapers, para coletar dados de páginas da web. Essas ferramentas simulam o comportamento de navega??o humana, permitindo que naveguem em sites, cliquem em links e extraiam informa??es do conteúdo HTML. Os dados extraídos podem incluir texto, imagens, links e outros elementos multimídia. Uma vez coletados, os dados podem ser armazenados em bancos de dados ou planilhas para posterior análise.
Os scrapers operam enviando solicita??es HTTP para sites e analisando as respostas HTML. Eles podem ser programados para seguir links, lidar com pagina??o e até mesmo interagir com aplicativos web complexos. Linguagens de programa??o populares para web scraping incluem Python, com bibliotecas como BeautifulSoup, Scrapy e Selenium, que oferecem funcionalidades robustas para extra??o de dados e automa??o da web.
Lutando com a falha repetida para resolver completamente os irritantes CAPTCHAs?
Descubra a solu??o automática de CAPTCHAs com a tecnologia de desbloqueio automático da web impulsionada por IA da Capsolver!
Solicite Seu Código de B?nus para as melhores solu??es de CAPTCHA; CapSolver: WEBS. Após resgatá-lo, você receberá um b?nus extra de 5% após cada recarga, Ilimitado.
A Legalidade do Web Scraping
Uma das concep??es err?neas mais comuns sobre o web scraping é que ele é ilegal. Isso n?o é verdade!
O web scraping é perfeitamente legal, desde que você siga certas diretrizes: adira às regulamenta??es do CCPA e GDPR, evite acessar dados protegidos por credenciais de login e n?o colete informa??es pessoalmente identificáveis. No entanto, isso n?o concede carta branca para raspar qualquer site indiscriminadamente. Considera??es éticas s?o cruciais, o que significa que você deve sempre respeitar os termos de servi?o do site, o arquivo robots.txt e as políticas de privacidade.
Em essência, o web scraping em si n?o é contra a lei, mas é importante aderir a regras e padr?es éticos específicos.
Casos de Uso do Web Scraping
No mundo orientado por dados de hoje, o valor dos dados superou o do petróleo, e a Web é uma fonte abundante de informa??es valiosas. Numerosas empresas em vários setores utilizam dados extraídos por meio de web scraping para aprimorar suas opera??es comerciais.
Embora existam inúmeras aplica??es de web scraping, aqui est?o algumas das mais prevalentes:
Compara??o de Pre?os
Usando ferramentas de web scraping, empresas e consumidores podem reunir pre?os de produtos de diferentes varejistas e plataformas online. Esses dados podem ser usados para comparar pre?os, encontrar as melhores ofertas e economizar tempo e dinheiro. Além disso, permite que as empresas monitorem as estratégias de pre?os dos concorrentes.
Monitoramento de Mercado
O web scraping permite que as empresas acompanhem tendências de mercado, disponibilidade de produtos e mudan?as de pre?os em tempo real. Ao manter-se atualizado com as informa??es mais recentes do mercado, as empresas podem adaptar rapidamente suas estratégias, aproveitar novas oportunidades e responder às demandas dos clientes em evolu??o. Essa abordagem proativa ajuda a manter uma vantagem competitiva.
Análise de Concorrência
Coletando dados sobre produtos, pre?os, promo??es e feedback dos clientes dos concorrentes, as empresas podem obter informa??es valiosas sobre os pontos fortes e fracos dos concorrentes. Ferramentas automatizadas também podem capturar instant?neos dos sites e esfor?os de marketing dos concorrentes, fornecendo uma vis?o abrangente para desenvolver estratégias para superá-los.
Gera??o de Leads
O web scraping revolucionou a gera??o de leads, transformando o que costumava ser um processo intensivo em m?o de obra em um processo automatizado. Extraindo informa??es de contato publicamente disponíveis, como endere?os de e-mail e números de telefone, as empresas podem rapidamente construir um banco de dados de leads potenciais. Essa abordagem simplificada acelera o processo de gera??o de leads.
Análise de Sentimentos
O web scraping permite a análise de sentimentos extraindo feedback de usuários de sites de avalia??o e plataformas de mídia social. Analisando esses dados, as empresas entendem a opini?o pública sobre seus produtos, servi?os e marca. Ganhando insights sobre os sentimentos dos clientes, as empresas podem melhorar a satisfa??o do cliente e abordar problemas de forma proativa.
Agrega??o de Conteúdo
O web scraping pode ser usado para agregar conteúdo de várias fontes em uma única plataforma. Isso é particularmente útil para sites de notícias, blogs e portais de pesquisa que precisam fornecer informa??es atualizadas de várias fontes. Automatizando a coleta de conteúdo, as empresas economizam tempo e garantem que suas plataformas permane?am atualizadas.
Listagens de Imóveis
O web scraping também é utilizado no setor imobiliário para reunir listagens de propriedades de vários sites. Esses dados ajudam agências imobiliárias e potenciais compradores a comparar propriedades, analisar tendências de mercado e tomar decis?es informadas. Automatizando a coleta de dados imobiliários, é possível obter uma vis?o abrangente do mercado.
Tipos de Scrapers
Os scrapers vêm em várias formas, cada um adaptado a diferentes propósitos e necessidades dos usuários. Geralmente, eles podem ser categorizados em quatro tipos principais, cada um oferecendo funcionalidades e benefícios únicos:
Scrapers de Desktop
Os scrapers de desktop s?o aplicativos de software aut?nomos instalados diretamente no computador do usuário. Essas ferramentas geralmente fornecem uma interface amigável, sem a necessidade de codifica??o, que permite aos usuários extrair dados por meio de intera??es simples de apontar e clicar. Os scrapers de desktop s?o equipados com recursos como agendamento de tarefas, análise de dados e op??es de exporta??o, atendendo tanto iniciantes quanto usuários avan?ados. Eles s?o adequados para tarefas de scraping em escala média e oferecem um bom equilíbrio entre funcionalidade e facilidade de uso.
Scrapers Personalizados
Os scrapers personalizados s?o solu??es altamente flexíveis desenvolvidas por programadores usando várias tecnologias. Esses scrapers s?o projetados para atender a requisitos específicos de extra??o de dados, tornando-os ideais para projetos complexos e de grande escala. Devido à sua natureza sob medida, os scrapers personalizados podem lidar com estruturas web intricadas, navegar por conteúdos din?micos e extrair dados de várias fontes de forma eficiente. Eles s?o a escolha ideal para empresas que exigem solu??es de scraping personalizadas que possam ser facilmente escaladas e adaptadas às necessidades em evolu??o.
Scrapers de Extens?o de Navegador
Os scrapers de extens?o de navegador s?o complementos para navegadores web populares, como Chrome, Firefox e Safari. Essas extens?es permitem que os usuários fa?am scraping de dados diretamente enquanto navegam em sites. Usando uma interface intuitiva de apontar e clicar, os usuários podem facilmente selecionar e extrair elementos de dados de páginas da web. Embora os scrapers de extens?o de navegador sejam eficazes para tarefas rápidas e de pequena escala, muitas vezes têm limita??es em termos de funcionalidade e escalabilidade em compara??o com outros tipos de scrapers.
Scrapers Baseados em Nuvem
Os scrapers baseados em nuvem operam na nuvem, fornecendo solu??es de scraping escaláveis e distribuídas. Esses scrapers s?o adequados para lidar com tarefas de extra??o de dados em grande escala e frequentemente vêm com capacidades integradas de processamento e armazenamento de dados. Os usuários podem acessar scrapers baseados em nuvem remotamente, agendar tarefas de scraping e gerenciar a extra??o de dados sem a necessidade de infraestrutura local. Embora ofere?am capacidades robustas para scraping de alto volume, sua flexibilidade em lidar com conteúdo web complexo e din?mico pode ser menor do que a dos scrapers personalizados.
Ao selecionar um scraper, é essencial considerar a complexidade da tarefa, o volume de dados a ser coletado e a escalabilidade e requisitos técnicos do projeto. Cada tipo de scraper tem suas próprias vantagens e casos de uso, e a escolha dependerá das necessidades específicas do usuário ou organiza??o.
Superando Desafios no Web Scraping
O web scraping, embora poderoso, também apresenta grandes obstáculos devido ao ambiente da internet em rápida mudan?a e às prote??es empregadas pelos sites. N?o é uma tarefa simples, e há uma alta probabilidade de
você enfrentar os seguintes tipos de problemas.
A principal dificuldade no web scraping decorre da dependência da estrutura HTML de uma página da web. Sempre que um site atualiza sua interface de usuário, os elementos HTML contendo os dados desejados podem mudar, tornando seu scraper ineficaz. Adaptar-se a essas mudan?as requer manuten??o constante e atualiza??o da lógica de scraping. Usar seletores de elementos HTML robustos que se adaptem a pequenas mudan?as na interface do usuário pode mitigar esse problema, mas n?o há uma solu??o única para todos os casos.
Infelizmente, mais complexidade está por vir, e é muito mais complexa do que a manuten??o.
Os sites implementam tecnologias sofisticadas para proteger seus dados de scrapers automatizados. Esses sistemas podem detectar e sinalizar solicita??es automatizadas, representando um obstáculo significativo. Aqui est?o alguns desafios comuns enfrentados pelos scrapers:
Proibi??es de IP: Os servidores monitoram as solicita??es recebidas em busca de padr?es suspeitos. Detectar software automatizado frequentemente leva à lista negra do IP, impedindo o acesso futuro ao site.
Restri??es Geográficas: Alguns sites restringem o acesso com base na localiza??o geográfica do usuário. Isso pode bloquear usuários estrangeiros de acessar determinados conteúdos ou apresentar dados diferentes com base na localiza??o, complicando o processo de scraping.
Limita??o de Taxa: Fazer muitas solicita??es em um curto período de tempo pode acionar medidas de prote??o contra DDoS ou proibi??es de IP, interrompendo a opera??o de scraping.
CAPTCHAs: Os sites frequentemente usam CAPTCHAs para distinguir entre humanos e bots, especialmente se for detectada atividade suspeita. Resolver CAPTCHAs programaticamente é altamente desafiador, frequentemente frustrando scrapers automatizados.
Embora resolver os três primeiros problemas possa ser resolvido trocando proxies ou usando um navegador de fingerprinting, o último CAPTCHA requer solu??es complexas que geralmente têm resultados inconsistentes ou só podem ser resolvidos por um curto período de tempo. Independentemente da técnica usada, esses obstáculos prejudicam a eficácia e estabilidade de qualquer ferramenta de web scraping.
Felizmente, existe uma solu??o para esse problema, e é o CapSolver, que oferece solu??es abrangentes para esses desafios. O CapSolver se especializa na resolu??o de CAPTCHAs e ajuda efetivamente no web scraping com tecnologia avan?ada para garantir um web scraping estável e eficaz. Integrando o CapSolver em seu fluxo de trabalho de scraping, você pode superar esses desafios. Aqui est?o alguns passos básicos.
Integrando Solucionadores de CAPTCHAs
Existem vários servi?os de solu??o de CAPTCHAs disponíveis que podem ser integrados em seu script de scraping. Aqui, usaremos o servi?o do CapSolver. Primeiro, você precisa se inscrever no CapSolver e obter sua chave de API.
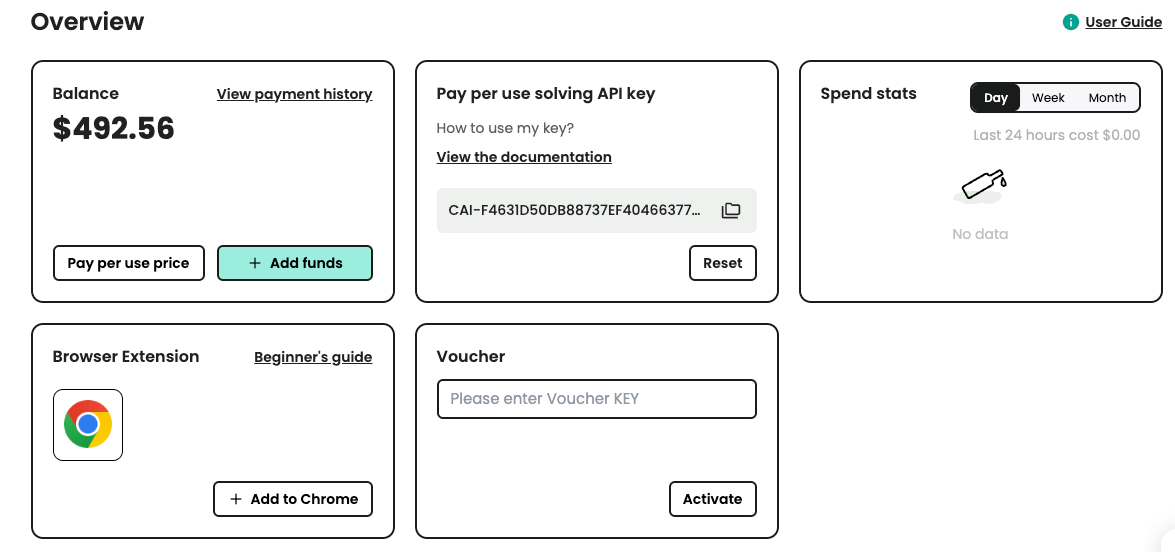
Etapa 1: Inscreva-se no CapSolver
Antes de estar pronto para usar os servi?os do CapSolver, você precisa ir ao painel do usuário e registrar sua conta.
Etapa 2: Obtenha sua Chave de API
Depois de registrado, você pode obter sua chave de API na página inicial do painel.
Exemplo de Código para CapSolver
Usar o CapSolver em seu projeto de web scraping ou automa??o é simples. Aqui está um exemplo rápido em Python para demonstrar como você pode integrar o CapSolver em seu fluxo de trabalho:
pythonCopy
# pip install requests
import requests
import time
# TODO: configure suas informa??es
api_key = "SUA_CHAVE_DE_API" # sua chave de API do CapSolver
site_key = "6Le-wvkSAAAAAPBMRTvw0Q4Muexq9bi0DJwx_mJ-" # chave do site do seu site alvo
site_url = "" # URL da página do seu site alvo
def capsolver():
payload = {
"clientKey": api_key,
"task": {
"type": 'ReCaptchaV2TaskProxyLess',
"websiteKey": site_key,
"websiteURL": site_url
}
}
res = requests.post("https://api.capsolver.com/createTask", json=payload)
resp = res.json()
task_id = resp.get("taskId")
if not task_id:
print("Falha ao criar a tarefa:", res.text)
return
print(f"ID da tarefa obtido: {task_id} / Obtendo resultado...")
while True:
time.sleep(3) # atraso
payload = {"clientKey": api_key, "taskId": task_id}
res = requests.post("https://api.capsolver.com/getTaskResult", json=payload)
resp = res.json()
status = resp.get("status")
if status == "ready":
return resp.get("solution", {}).get('gRecaptchaResponse')
if status == "failed" ou resp.get("errorId"):
print("Solu??o falhou! Resposta:", res.text)
return
token = capsolver()
print(token)
Neste exemplo, a fun??o capsolver envia uma solicita??o à API do CapSolver com os par?metros necessários e retorna a solu??o CAPTCHA. Esta integra??o simples pode economizar inúmeras horas e esfor?o na resolu??o manual de CAPTCHAs durante tarefas de web scraping e automa??o.
Conclus?o
O web scraping transformou a forma como coletamos e analisamos dados online. Desde compara??es de pre?os até tendências de mercado e gera??o de leads, suas aplica??es s?o diversas e poderosas. Apesar dos desafios impostos por medidas anti-scraping, como CAPTCHAs, solu??es como o CapSolver permitem processos de extra??o de dados mais suaves.
Seguindo diretrizes éticas e aproveitando ferramentas avan?adas, empresas e desenvolvedores podem aproveitar todo o potencial do web scraping. N?o se trata apenas de coletar dados; trata-se de desbloquear insights, impulsionar a inova??o e manter a competitividade no cenário digital atual.
Declara??o de Conformidade: As informa??es fornecidas neste blog s?o apenas para fins informativos. A CapSolver está comprometida em cumprir todas as leis e regulamentos aplicáveis. O uso da rede CapSolver para atividades ilegais, fraudulentas ou abusivas é estritamente proibido e será investigado. Nossas solu??es de resolu??o de captcha melhoram a experiência do usuário enquanto garantem 100% de conformidade ao ajudar a resolver dificuldades de captcha durante a coleta de dados públicos. Incentivamos o uso responsável de nossos servi?os. Para mais informa??es, visite nossos Termos de Servi?o e Política de Privacidade.